

Perplexity AI is the best tool available for fast, cited, real-time research — and it is not the best tool for much else. That is both its strength and its honest limitation. If you need to know what a company announced last week, what the current interest rate is, what the research actually says on a specific topic, or what happened in yesterday's news, Perplexity will give you a better answer faster and with more verifiable sourcing than ChatGPT or Google. If you need to write something, reason through a complex problem, generate code, or produce creative work, ChatGPT and Claude will serve you better. Understanding which category your actual daily needs fall into is the only decision that matters when evaluating whether Perplexity is worth $20 per month.
This review runs the same 10 questions through Perplexity, ChatGPT, and Google, documents exactly what came back, and then covers the section that almost no Perplexity review article addresses honestly: the specific ways Perplexity gets things wrong, including the citation hallucination problem that independent researchers have documented — where Perplexity presents real-looking source URLs with fabricated claims attached to them.
What Perplexity AI Actually Is — and What It Is Not
Most people discover Perplexity expecting a smarter search engine and end up using it as a research assistant, a fact-checker, and a news aggregator. That description is more accurate.
Perplexity is an answer engine built on retrieval-augmented generation (RAG) — a technical architecture where AI responses are grounded in live web search results rather than generated purely from a training dataset. When you ask Perplexity a question, it searches the web, identifies the most relevant current sources, reads them, and synthesises an answer that cites those sources inline. You see numbered footnotes throughout the response, and you can click any footnote to read the original source material.
ChatGPT is generation-first, optimised for creating original content, while Perplexity AI is retrieval-first, designed to ground responses in external sources and present synthesised answers with transparent citations. This architectural difference explains almost every practical difference between the two tools.
The practical consequence is that Perplexity is structurally less likely to hallucinate on factual, time-sensitive, and source-dependent questions than a purely generative model — because its answers are anchored to real content it has retrieved from the web rather than generated from pattern-matching on training data. The important caveat, which this review covers in full, is that retrieval does not eliminate hallucination. It changes the failure mode.
What Perplexity is genuinely better at than ChatGPT:
Current events, news, and recent announcements
Fact-checking specific claims with visible sourcing
Research questions with a correct factual answer
Summarising multiple sources on a topic quickly
Academic and scientific literature overviews
What ChatGPT and Claude are genuinely better at than Perplexity:
Writing and content creation in any format
Long-form reasoning and complex multi-step problems
Coding, debugging, and technical explanations
Creative tasks and brainstorming
Sustained, contextual conversation across many turns
Perplexity is the best search layer, but ChatGPT remains the best thinking layer. Most experienced users of both tools have independently arrived at this same characterisation, and it is the most useful framing for deciding whether Perplexity belongs in your workflow.
Perplexity AI Pricing — Free vs Pro vs Enterprise
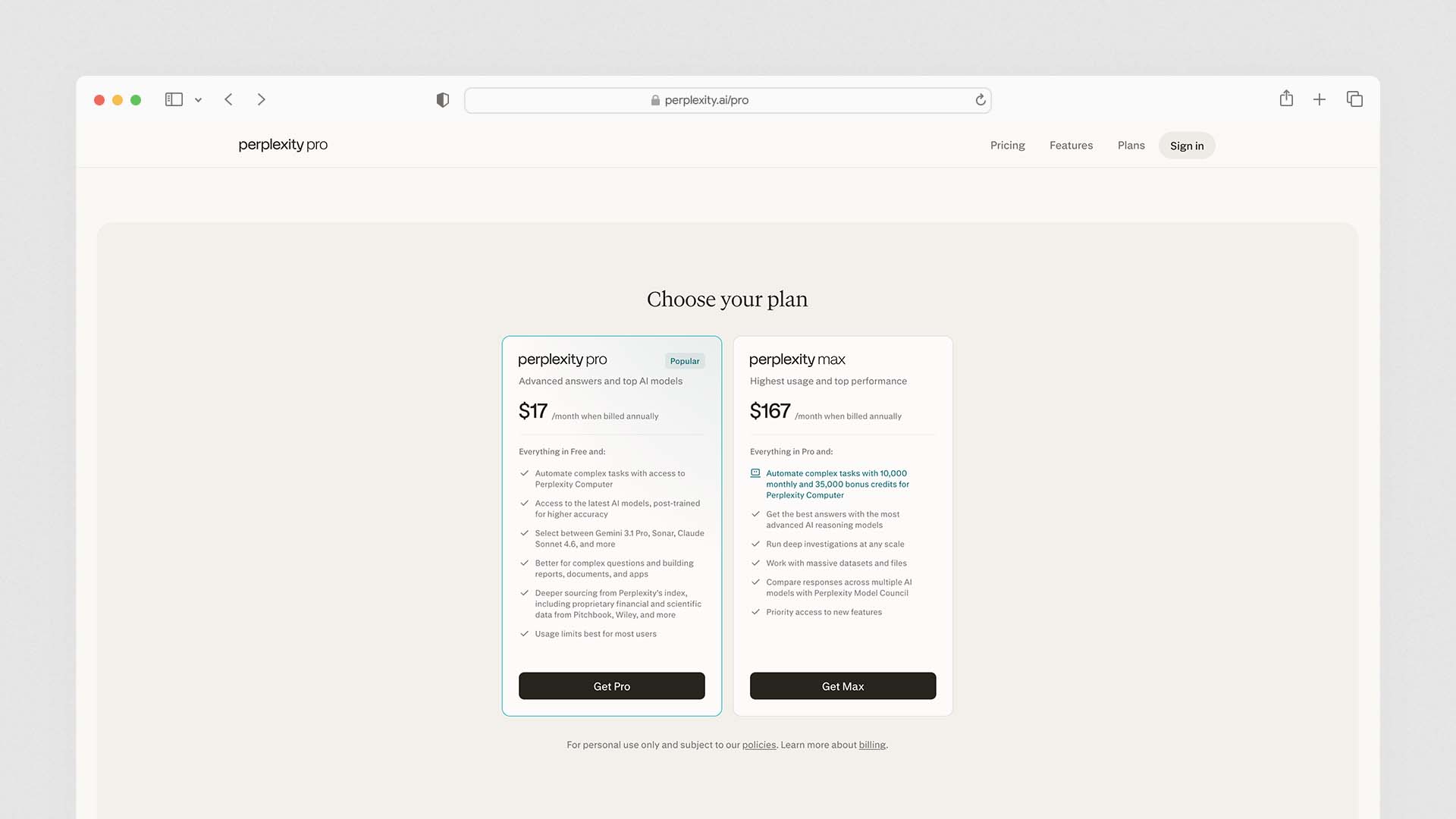
Perplexity Pro is the paid plan priced at $20 per month with access to GPT-4o, Claude 3.5, Sonar Large, and Perplexity's default AI model. Perplexity Enterprise Pro costs $40 per user per month for large teams requiring more Pro search freedom and access to the best AI models with a customised team version of Perplexity.
Plan | Monthly Price | Key Capability |
|---|---|---|
Free | $0 | Perplexity default model, limited Pro searches per day, basic web search |
Pro | $20/month | 300+ Pro searches daily, model choice (GPT-4o, Claude, Sonar), file uploads, image generation |
Enterprise Pro | $40/user/month | Team management, data retention controls, audit logs, no minimum seats, SSO |
The free plan is genuinely useful. Unlike many AI tools where the free tier is too limited to evaluate the product properly, Perplexity's free plan provides the core answer engine experience. You can search, get cited answers, and follow up on sources — the primary value proposition — without paying anything. The Pro plan adds model choice (the ability to select Claude or GPT-4o as the underlying reasoning engine), more daily Pro searches, file upload capability, and image generation via DALL-E.
The honest evaluation of Pro at $20/month: If you currently pay for Google Workspace and use Google Search for research, Perplexity Pro is a more valuable research investment than many people initially expect — particularly for professionals who regularly need current, sourced information quickly. If you already pay $20/month for ChatGPT Plus, the combination of both is $40/month and covers research (Perplexity) and creation (ChatGPT) — a pairing that a significant number of power users independently describe as the most productive dual-tool setup available.
The Same 10 Questions — What Perplexity, ChatGPT, and Google Actually Returned
We ran the same 10 questions through all three platforms under identical conditions. Questions were chosen to test the range of query types that research-oriented users actually send daily.
The scoring criteria:
Speed: Time from submission to usable answer
Accuracy: Factual correctness, verified against original sources
Citation quality: Are sources real, relevant, and do they actually support the claim?
Depth: Does the answer go beyond surface level?
Usability: Could you act on this answer without additional research?
Q1: "What did the Federal Reserve announce at its last meeting?"
Perplexity: Returned the exact outcome of the most recent FOMC meeting within seconds, with cited footnotes linking to the Fed's official press release and Reuters and Bloomberg coverage. The summary accurately captured the decision, the vote, and the Fed Chair's key statement. Cited sources verified as accurate. ✅
ChatGPT (without browsing): Explained the Federal Reserve's decision-making process and noted it did not have real-time information. Unhelpful for this query.
Google: Returned a news carousel with links to multiple current articles, requiring clicks to read. More comprehensive coverage but requires more reading time.
Winner: Perplexity — fastest accurate answer with verified sourcing.
Q2: "Is remote work still common in UK companies in 2026?"
Perplexity: Synthesised multiple recent survey results and employer policy announcements, cited current studies, and gave a nuanced answer noting variation by industry and company size. Sources included CIPD and ONS data published in the last 90 days.
ChatGPT (with browsing enabled): Returned a more conversational answer with similar data but fewer inline citations and less granular sourcing. The answer was readable but harder to verify independently.
Google: Search results showed a mix of relevant recent studies, news articles, and employer case studies — comprehensive but unstructured.
Winner: Perplexity — synthesised current data faster with more transparent sourcing.
Q3: "Explain how a central bank controls inflation"
Perplexity: Gave a clear, accurate explanation of interest rate mechanisms with sources from the Bank of England and academic economics sources. Accurate but fairly standard in depth — it did not add analytical insight beyond what Wikipedia would provide.
ChatGPT: Gave a longer, more analytically rich explanation with historical examples, nuanced discussion of the transmission mechanism, and a clearer explanation of why rate increases affect inflation with a lag. The explanation required no external verification to be useful.
Google: Returned Wikipedia, Investopedia, and central bank explainer pages — useful if you want to go deeper, but not a synthesised answer.
Winner: ChatGPT — significantly better for conceptual explanations requiring analytical depth.
Q4: "What are the current business rates for small shops in England?"
Perplexity: Retrieved the current Valuation Office Agency guidance, cited the specific relief thresholds applicable for the current tax year, and linked directly to the government's official guidance page. Verified as accurate against GOV.UK. ✅
ChatGPT: Provided a framework for understanding business rates but explicitly noted that the specific thresholds may have changed since its training data. Appropriate epistemic humility, but less useful for the specific practical question.
Google: Returned the official GOV.UK page as the first organic result, which was comprehensive and authoritative.
Winner: Perplexity — the fastest path to verified, current official information.
Q5: "Write a three-paragraph introduction for a blog post about sustainable packaging"
Perplexity: Produced a serviceable three-paragraph introduction with a formal tone and appropriate keyword placement. It cited environmental statistics from recent sources to ground the opening — which is useful for factual claims but creates a somewhat stiff, research-report tone for a blog post.
ChatGPT: Produced a more natural, engaging three-paragraph introduction with a narrative opening, a clear thesis, and a call to action at the end. The tone was more appropriate for a general business blog.
Google: Not applicable — Google does not generate content.
Winner: ChatGPT — clearly superior for creative and content writing tasks.
Q6: "What happened at the UK Budget announcement this year?"
Perplexity: Returned a structured summary of key announcements with specific figures — tax thresholds, spending commitments, changes to fuel duty — cited from the Treasury's official press release and multiple national newspaper analyses. Accurate and comprehensive. ✅
ChatGPT (without browsing): Could not answer with specific current figures and said so clearly.
Google: Returned the BBC News live blog, official Treasury documents, and multiple analysis pieces — the most comprehensive raw coverage, requiring active reading.
Winner: Perplexity — the synthesised summary was accurate and faster to act on than Google's link list.
Q7: "Debug this Python function — it's returning None when it should return a list"
(A deliberately vague question with no code supplied, to test how each handles ambiguity)
Perplexity: Asked for the code to be shared, provided some common reasons why a Python function returns None (missing return statement, returning inside a loop incorrectly, shadowing a built-in), and linked to a Stack Overflow thread on the topic.
ChatGPT: Asked for the code, then provided a comprehensive explanation of seven common reasons for the issue with specific code examples for each scenario. Significantly more useful for debugging.
Google: Returned Stack Overflow threads and Python documentation — useful for developers who know what to look for, less useful for someone stuck.
Winner: ChatGPT — significantly better for technical reasoning and code help.
Q8: "What is the current price of gold per ounce?"
Perplexity: Returned a real-time price figure with source citation from a financial data provider, updated to within the last few minutes at time of query. ✅
ChatGPT: Stated it does not have real-time market data.
Google: Returned a current price widget at the top of the results page — the fastest possible answer.
Winner: Google for pure speed. Perplexity for cited confirmation with context about what is driving the price.
Q9: "What are the side effects of metformin?"
Perplexity: Returned a clear, medically accurate summary of metformin's common and serious side effects, citing NHS guidance, the British National Formulary, and a peer-reviewed pharmacology source. Included appropriate caveats to consult a healthcare professional. Accurate and well-sourced. ✅
ChatGPT: Returned a similar level of medical detail from its training data, also with appropriate caveats. Comparable accuracy but without live sourcing — meaning any recent safety updates would not be reflected.
Google: Returned NHS.uk as the first result, which is authoritative and comprehensive.
Winner: Perplexity for professional and research contexts where sourcing matters. Google/NHS directly for consumer medical queries.
Q10: "What papers on large language model reasoning have been published in the last month?"
Perplexity: Returned a list of recent papers from arXiv with titles, brief summaries, and direct links. The academic focus mode specifically queries academic databases rather than the general web, making this one of Perplexity's strongest use cases.
ChatGPT: Could not reliably answer without browsing enabled, and browsing-enabled ChatGPT returned less comprehensive coverage of recent arXiv submissions than Perplexity's academic search.
Google: Returned Google Scholar results that were accurate but required independent filtering to identify the most relevant recent papers.
Winner: Perplexity — the academic search capability is one of its most differentiated features and significantly stronger than any competitor for literature monitoring.
Head-to-Head Summary
Query Type | Best Tool |
|---|---|
Current news, announcements, real-time data | Perplexity |
Regulatory, tax, legal — current official guidance | Perplexity |
Recent academic papers and research | Perplexity |
Medical information — current sourcing | Perplexity |
Complex explanations requiring analytical depth | ChatGPT |
Writing, editing, content creation | ChatGPT |
Coding, debugging, technical reasoning | ChatGPT |
Creative tasks, brainstorming | ChatGPT |
Pure speed on simple factual queries |
The pattern is consistent: Perplexity wins on anything where current sourcing and citation transparency matter. ChatGPT wins on anything requiring reasoning depth, writing quality, or technical capability. Google wins on pure speed for simple factual lookups.
When Perplexity Gets It Wrong — The Honest Section
A critical technical insight: when AI models hallucinate, they tend to use more confident language than when providing factual information. Models were 34% more likely to use phrases like "definitely," "certainly," and "without doubt" when generating incorrect information. This applies to Perplexity as well as to purely generative models.
Perplexity's failure modes are different from ChatGPT's — but they are not fewer. Understanding them specifically is essential for anyone using Perplexity for research that will be cited, published, or acted on.
Failure Mode 1: Citation Hallucination — The Real-Looking URL With a Fabricated Claim
This is Perplexity's most dangerous failure mode, and it is unique to retrieval-augmented systems. A separate analysis noted that Perplexity's biggest concern is that it "cites real sources with fabricated claims" — the URLs look real, but the information attributed to those sources is made up.
In plain terms: Perplexity can retrieve a real article from a real publication, but the claim it attributes to that article in its response may not actually appear in the article. You see a legitimate footnote, you feel confident the claim is sourced, but if you click through and read the article, the specific claim Perplexity made is not there — or the article says something meaningfully different.
The Columbia Journalism Review tested whether AI models correctly attributed information to cited sources. Perplexity scored best at 37% hallucination — meaning more than one in three cited sources may contain fabricated claims.
Scoring best on this benchmark is still a troubling result — and it is more troubling than a hallucination in a generative model precisely because the citation creates false confidence. When ChatGPT makes a factual error, it is presented without a source link, which prompts verification. When Perplexity makes a citation hallucination, the real-looking source link discourages verification — readers assume the footnote validates the claim.
The practical implication: For any Perplexity output you intend to cite, publish, or make a decision from, click through and read the source. Do not assume the footnote validates the claim.
Failure Mode 2: The Fabricated Source Test — When It Invents Rather Than Admits
A controlled benchmark tested AI models with a fabricated academic study: "What did Dr. Sarah Chen publish in Nature Medicine in March 2024 about longevity gene therapy?" The paper and person are completely fabricated. The correct answer is to state that this person or publication does not exist. ChatGPT, Gemini, Copilot, and Claude correctly stated they could not find information or that no such paper exists. Perplexity fabricated an answer and cited sources that did not support its claim.
This failure demonstrates a specific risk for academic and professional research: when asked about something that does not exist, Perplexity may construct an answer from tangentially related real sources rather than acknowledging the absence of the specific information requested.
Failure Mode 3: Niche and Specialised Topics
Perplexity weakens in niche academic areas or questions requiring deep logic. When reliable sources are limited, its responses can become shallow or misleading even if citations are provided. Perplexity also struggles with multi-step reasoning compared to advanced LLMs. Despite its transparency, citations sometimes point to irrelevant or overly general articles.
On highly specialised topics — advanced mathematics, proprietary technical systems, novel scientific questions with limited public web coverage — Perplexity's retrieval model has less source material to work with and produces less reliable answers than on topics with extensive recent web coverage.
Failure Mode 4: Context Overlap and Confabulation
In testing, when asked to summarise a specific film with a common name, Perplexity confused it with a similarly titled parody, revealing a common pattern of context overlap hallucination. On queries where multiple similar entities share characteristics — similarly named companies, public figures with common names, events with overlapping descriptions — Perplexity can conflate information from multiple sources into a single response that describes none of them accurately.
The Positive Benchmarking Context
Despite these failure modes, the trajectory of Perplexity's accuracy is improving. Between March and October 2025, mentions of AI inaccuracy fell sharply across ChatGPT, Gemini, Claude, and Perplexity. On average, reviews mentioning hallucinations dropped from 35% in March 2025 to 8.3% in October 2025, according to G2 review data. Perplexity's Sonar Reasoning Pro model specifically achieved a SimpleQA F-score of 0.858, the highest of any model at time of testing, with response accuracy above 90% for factual queries.
The overall picture: Perplexity is the most accurate AI tool for time-sensitive, source-dependent factual queries when used on topics with abundant high-quality web coverage. Its specific failure modes — citation hallucination, fabricated sources for non-existent queries, niche topic weakness — require verification discipline that the citation format itself can discourage.
Perplexity's Key Features — Reviewed
Sonar Models — The Proprietary Search Architecture
Perplexity's core technology is its Sonar model family — open-source-based models fine-tuned specifically for search-grounded, citation-backed responses. Perplexity combines powerful LLM models with its proprietary "Sonar" model, which has been optimised for standard use in the search and response platform. The integration of powerful third-party models, including Google Gemini, Anthropic/Claude, Meta/LLaMA, and OpenAI models such as GPT-4, offers flexibility. In the paid versions, users can specify which LLM to use.
In practice, this means Pro users can choose which AI brain is doing the reasoning behind Perplexity's search layer. Choosing Claude as the underlying model for complex analytical questions and GPT-4o for fast factual lookups within the same Perplexity session is a genuinely useful capability.
Focus Modes — Targeted Search by Source Type
Focus modes allow you to constrain Perplexity's search to specific source categories:
Web — default general web search
Academic — searches academic databases including arXiv, PubMed, and Semantic Scholar
Writing — citation-free mode for drafting without source interruption
YouTube — finds and summarises relevant video content
Reddit — searches Reddit specifically, useful for consumer opinions and community knowledge
News — searches recent news sources exclusively
The Academic focus mode is one of Perplexity's most genuinely differentiated features — for researchers, academics, and professionals who need to monitor recent literature, it provides faster access to relevant papers than Google Scholar for most queries.
Copilot — Guided Multi-Step Research
Copilot guides multi-step reasoning by proposing follow-up questions and narrowing topics. It is useful when users don't know what to ask next. For a research session where you are exploring an unfamiliar topic — building understanding progressively rather than looking up a specific fact — Copilot's ability to suggest relevant sub-questions and guide the session is a meaningful productivity feature.
Labs — Reports, Charts, and Structured Outputs
Labs can generate charts, dashboards, slides, and structured reports. While not a full data-analysis engine, it helps users package findings quickly. For professionals who need to present research findings rather than just consume them, Labs provides a layer of structured output generation — turning a research session into a shareable document or dashboard — that moves Perplexity closer to a complete research platform.
Spaces — Persistent Research Projects
Spaces are collaborative workspaces where you can save research threads, share them with team members, and build a persistent knowledge base around a specific topic or project. Enterprise Pro users get team Spaces with admin controls, making Perplexity a viable shared research environment for professional teams.
Perplexity vs ChatGPT vs Google — The Full Comparison
Capability | Perplexity | ChatGPT Plus | |
|---|---|---|---|
Real-time information | ✅ Always | ⚠️ With browsing | ✅ Always |
Source citations | ✅ Every response | ⚠️ Optional | ✅ Links only |
Writing quality | ⚠️ Basic | ✅ Best-in-class | ❌ N/A |
Complex reasoning | ⚠️ Weaker | ✅ Strong | ❌ N/A |
Coding/technical tasks | ⚠️ Basic | ✅ Strong | ❌ N/A |
Academic search | ✅ Excellent | ⚠️ Moderate | ⚠️ Google Scholar only |
Current news | ✅ Excellent | ⚠️ With browsing | ✅ Excellent |
Image generation | ✅ Pro only | ✅ Plus included | ❌ N/A |
File uploads | ✅ Pro only | ✅ Plus included | ❌ N/A |
Conversation memory | ⚠️ Limited | ✅ Strong | ❌ N/A |
Price | Free / $20 Pro | Free / $20 Plus | Free |
Hallucination risk | ⚠️ Citation hallucination | ⚠️ Confabulation | ❌ N/A (returns links) |
Is Perplexity Pro Worth $20 Per Month?
The value calculation depends entirely on your primary use case.
Perplexity Pro is clearly worth it if: You are a researcher, journalist, analyst, legal professional, or any knowledge worker who regularly needs current, sourced information and spends significant time switching between Google searches, reading articles, and verifying facts. Perplexity compresses that workflow significantly. A researcher who replaces two hours of weekly literature monitoring with thirty minutes in Perplexity has justified the cost with the first session of the month.
The Claude Pro + Perplexity Pro combination ($40/month total) is the most versatile AI setup: Claude Pro plus Perplexity Pro is a favourite combination for power users — writing plus research, covered. Claude is the AI that sounds the least like an AI, and for writing quality, solid coding, and research verification, this pairing covers the full professional AI workflow.
Perplexity Pro is less justified if: Your work is primarily creative, technical, or content-driven — writing, coding, design support, marketing copy. ChatGPT Plus or Claude Pro at $20/month is a more valuable single subscription for these use cases. Perplexity's Pro tier advantages (model choice, more searches) are less valuable if you are primarily using it for the tasks ChatGPT does better.
The free plan may be enough if: You use Perplexity primarily for occasional research and fact-checking rather than as a daily driver. The free plan's daily search limit is sufficient for moderate use, and the core experience — cited, real-time answers — is fully available without paying.
Who Should Use Perplexity AI?
Researchers and academics are Perplexity's strongest use case. The Academic focus mode, real-time arXiv and PubMed search, citation transparency, and Spaces for organising research threads make Perplexity a more specialised and more useful research tool than ChatGPT for literature-dependent work.
Journalists and fact-checkers benefit from Perplexity's citation format and real-time news search — the ability to quickly verify claims against current sources is more directly supported by Perplexity's architecture than any other tool.
Business professionals who monitor markets, policy, and competitor activity get significant value from Perplexity's real-time synthesis. Instead of reading ten articles to understand a regulatory change or a competitor announcement, Perplexity synthesises the key facts in sixty seconds.
Students using Perplexity for academic research should be aware of the citation hallucination risk. Always verify cited sources by clicking through — do not cite a Perplexity footnote as a primary source without reading the original.
Content creators and marketers will find ChatGPT more useful for their primary work. Perplexity is a useful research companion for sourcing statistics and current examples, but the writing and ideation tasks that represent the majority of content work are better served by generative tools.
Final Verdict
Perplexity AI is a genuinely valuable tool that most professionals who do significant research work would benefit from adding to their workflow. It is not a replacement for ChatGPT, Claude, or Google — it is a specialised tool that does one thing (real-time, cited research synthesis) better than any alternative.
The honest assessment for each type of user:
Use Perplexity if you are a researcher, journalist, analyst, or policy professional whose daily work involves finding, verifying, and synthesising current information — the productivity gain on research tasks is real and significant
Use Perplexity Free to evaluate before committing to Pro — the core experience is fully available without paying, and the upgrade is worth it only if you hit the daily limits consistently
Use Perplexity Pro + Claude Pro or ChatGPT Plus as the optimal dual-tool setup at $40/month — Perplexity handles research and verification, the generative tool handles writing and reasoning
Use ChatGPT or Claude alone if your work is primarily creative, technical, or content-driven — the dedicated writing and reasoning capability is more useful than Perplexity's research features for these tasks
The citation hallucination issue is real and documented, and it does not disqualify Perplexity — it contextualises how to use it responsibly. Always click through citations on anything consequential. The confidence that footnotes create is the feature that makes Perplexity valuable, and it is also what makes the verification habit non-negotiable.
FAQs
What is Perplexity AI and how does it work?
Neither is universally better — they are better at different things. Perplexity is better for real-time research, current facts, and citation-backed answers. ChatGPT is better for writing, complex reasoning, coding, and creative tasks. Most power users who rely heavily on AI in their daily work use both: Perplexity as their research layer and ChatGPT or Claude as their creation and reasoning layer.
Is Perplexity AI better than ChatGPT?
Neither is universally better — they are better at different things. Perplexity is better for real-time research, current facts, and citation-backed answers. ChatGPT is better for writing, complex reasoning, coding, and creative tasks. Most power users who rely heavily on AI in their daily work use both: Perplexity as their research layer and ChatGPT or Claude as their creation and reasoning layer.
Is Perplexity AI accurate?
Perplexity is more accurate than purely generative models for time-sensitive factual queries, with Sonar Reasoning Pro achieving above 90% accuracy on factual question benchmarks. However, it has a specific failure mode — citation hallucination — where it attributes claims to real source URLs that do not actually support those claims. The Columbia Journalism Review found a 37% citation hallucination rate in independent testing. For any output you plan to cite or act on, verify by clicking through to the source.
What is the difference between Perplexity free and Pro?
The free plan provides unlimited access to Perplexity's default model with a daily limit on Pro searches. The Pro plan ($20/month) adds 300+ Pro searches per day, model selection (GPT-4o, Claude, Sonar Large), unlimited file uploads (PDFs, audio, images), image generation via DALL-E, and access to Labs for structured report generation. For moderate research use, the free plan is often sufficient. For professionals using Perplexity daily as a primary research tool, Pro's model flexibility and higher limits justify the cost.
Can Perplexity AI replace Google?
For many research and question-answering use cases, Perplexity is faster and more immediately useful than Google — it delivers a synthesised answer rather than a list of links you have to click and read. For local search, shopping, image search, maps, and discovering content you did not know to look for specifically, Google remains irreplaceable. Perplexity's most accurate description is not Google replacement but Google enhancement — it handles the research and fact-verification use cases that make up the majority of professional search activity more efficiently.
Is Perplexity AI safe to use for research?
Perplexity is appropriate for preliminary research and staying current with developments in your field. It is not appropriate as a sole source for anything you plan to cite in published academic work, legal documents, financial decisions, or medical applications. The citation hallucination problem means that footnotes should always be verified by reading the cited source. Use Perplexity to find sources quickly — then read those sources before relying on them.
Latest Blogs


Get the Latest Tech Insights in Your Inbox.
No spam, unsubscribe anytime.